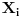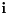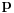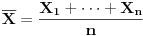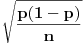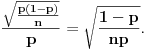Recimo da statistički ocenjuješ koliko se nekakva pojava često javlja pod nekim uslovima. Ako je obim uzorka recimo
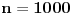
i činjenična učestanost te pojave pri tim uslovima je na primer
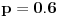
(u proseku se dešava u 6 od 10 slučajeva), onda će ocena te učestanosti biti oko
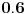
, ali ne baš tačno, nego blizu. Očekivana apsolutna grešku je
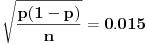
,
odnosno očekivana relativna greška će biti
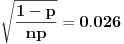
.
Ako je pak uzorak takođe obima
, a stvarna učestanost pojave je
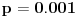
(u proseku se dešava jednom u 1000 slučajeva), onda će ocena te učestanosti biti oko
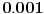
, ali ne baš tačno. Očekivana apsolutna greška je
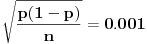
,
odnosno očekivana relativna greška će biti
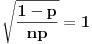
.
Dakle, što je pojava ređa, relativna greška ocene njene učestanosti uzorkom istog obima je veća.
Prema tome, pošto je Linux slabo zastupljen, relativna greška merenja njegove zastupljenosti je veća nego za na primer macOS, koji je zastupljeniji.
To objašnjava onolike oscilacije u brojkama iz meseca u mesec u podacima netmarketshare-a.
Na osnovu tih brojki koje objavljuje netmarketshare se može oceniti kolikim uzorkom barataju.
Nije bitno koji su zaključci izvučeni, već kako se do njih došlo.

 Re: Linux prebacio 2%
Re: Linux prebacio 2%