Citat:
Citat:
Citat: Ivan Dimkovic:
Vidi, zakon o informaciji za informaticare ti je isto sto i zakon termodinamike za fizicare - danas se manje-vise uzima za nesto sto se uopste ne dovodi u pitanje, i to sa debelim razlogom.
2.Mislim da ga nisam ugrozio, to sto neki tvrde da sve pokusavam da spakujem u 16 bajta ili 1 double znak je da nisu dobro procitali kako izgleda kompresovan fajl.
I ja bih rekao da ga nisi ugrozio, taman posla. Tvoj algoritam ima dva problema:
1) Jako je nepraktičan jer ima eksponencijalnu složenost.
2) Zapravo ne uradi ništa sa podacima, već je u najboljem slučaju samo permutacija na skupu svih datoteka zadate dužine N. Inverz se uvek lako nađe kao inverzna permutacija (u smislu da je lako napisati algoritam; samo treba sačekati jaaako dugo da se izvrši, da zanemarimo to sad), ali na žalost odnos veličina datoteke posle i pre kompresije ne može biti manji od 1.
Iako u novinama s vremena na vreme mogu da se pročitaju priče o neverovatnim algoritmima za kompresiju (ovde se recimo vrti priča, izdaju knjige i pišu hvalospevi o izvesnom inženjeru koji je smislio neverovatan sistem za kompresiju, ali je umro dan pre nego što će u Filipsu (Philips) napraviti demo i potpisati ugovor vredan više milijardi čvrste valute; naravno i svi njegovi spisi i laboratorijski logovi su misteriozno nestali), kompresija
nije nikakva mitologija. U pitanju je deo teorije informacija koja je vrlo dobro utemeljena matematička disciplina. Iako put do savršene kompresije nije zacrtan, tačno je poznato
dokle ta savršena kompresija može da komprimuje datoteku. Ako recimo hoćeš da kompresuješ datoteku dužine N, jedini, ali
zaista jedini način da to uspeš jeste da nekako znaš da se od svih mogućih datoteka dužine N
ne mogu javiti baš sve datoteke. Pretpostavimo da nekako znamo koje se datoteke javljaju a koje ne javljaju. Onda napravimo prenumeraciju: jedan brojač koji broji preko svih datoteka koje
mogu da se jave. Pošto njih ima manje od
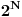
, brojač je manje dužine od polazne datoteke pa smo dobili kompresiju. To je tvoja osnovna ideja koja je gore izložena.
Problemi su: 1) to jako dugo traje, 2) ne postoji jednostavan način da znamo koja se datoteka može pojaviti a koja ne i 3) ako sigurno znamo da je svaka od
datoteka moguća onda je
apsolutno nemoguće išta kompresovati bez gubitaka. 1) je očigledno, jer je algoritam eksponencijalan. 3) je dokazao Šenon. 2) je problematično jer je praktično
nemoguće napraviti brojač koji bi radio to što želiš. Zato se ljudi pomažu statistikom koja je u neku ruku
surogat za univerzalno znanje o svim datotekama. Statistike naravno zavise od uzorka (podsećanje: statistika je funkcija na skupu slučajnih promenljivih) a pošto su uzorci razni (slika, zvuk, datoteke, tekst itd), to imaš mnogo različitih statistika koje rade dobro u nekom ograničenom opsegu slučajeva.
Drugim rečima: ideja koju imaš je
ispravna u principu, ali od nje
nikada neće direktno da ispadne neki koristan algoritam — osim u slučaju da
tačno znaš raspodelu svih datoteka — u kom slučaju je sasvim opravdano ono što si rekao da ti je bog došapnuo: on je verovatno jedini kandidat za takvo univerzalno znanje. (U računarskoj terminologiji se radije koristi izraz
oracle, što izbegava religiozne konotacije).
Za kraj, da iskomentarišem onu Ivanovu referencu na Šenona i da bacim par linkova.
Nekad jeste lepo vratiti se i popiti vodu sa izvora, ali od Šenonovog vremena pojavili su se
ljudi koji teoriju informacija objašnjavaju na
daleko lepši i lakši način. (Na žalost pomenute knjige nema na Internetu a i malo je skupa.)
Od javno dostupnih knjiga za čitanje preporučujem knjigu (koja je
izašla na hartiji ali je
dostupna i online)
Dejvida Mekkeja (David MacKay), koja odlično i matematički precizno opisuje mnoge probleme koji imaju veze sa teorijom informacija. Kompresija je samo jedna od njih.
Dejvid Mekkej je inače jedan od nekoliko ljudi koji su izmislili danas najefikasnije metode kodiranja tako da bi trebalo da zna šta priča, knjiga je puna slika i primera koji pokazuju čemu sve to služi i od nje možete da napravite 3 do 4 prilično zahtevna kursa za neke redovne, odnosno postdiplomske studije. Uzgred, tu se nalazi i problem Šeširdžija koji se pojavio u forumu Matematika pre nekoliko meseci.
Takođe možete pogledati i [url=http://lthc
www.epfl.ch/mct/index.php]knjigu u pripremi Ruedigera Urbankea[/url] koja se doduše bavi kodiranjem za prenos podataka (što je „druga strana medalje“ od kompresije) i takođe je [url=http://lthc
www.epfl.ch/papers/mct.ps]dostupna online[/url].
Samo da napomenem da nemam nameru da pridikujem kako treba ili ne treba prilaziti kompresiji podataka. Ako pogledate gore pomenute knjige i prošarate Internetom videćete da o kompresiji svakako nije rečena poslednja reč. Ali kao što ćete se složiti da nema smisla da budem stolar ako nemam alat — čekić, eksere, turpiju itd. — tako nema mnogo smisla baviti se i kompresijom podataka a da se ne pročitaju osnovne stvari.
f




 Re: beskonacna kompresija - konacno resenje
Re: beskonacna kompresija - konacno resenje
