



 Re: Konverzija ćirilice u latinicu i linkovi
Re: Konverzija ćirilice u latinicu i linkoviCitat:
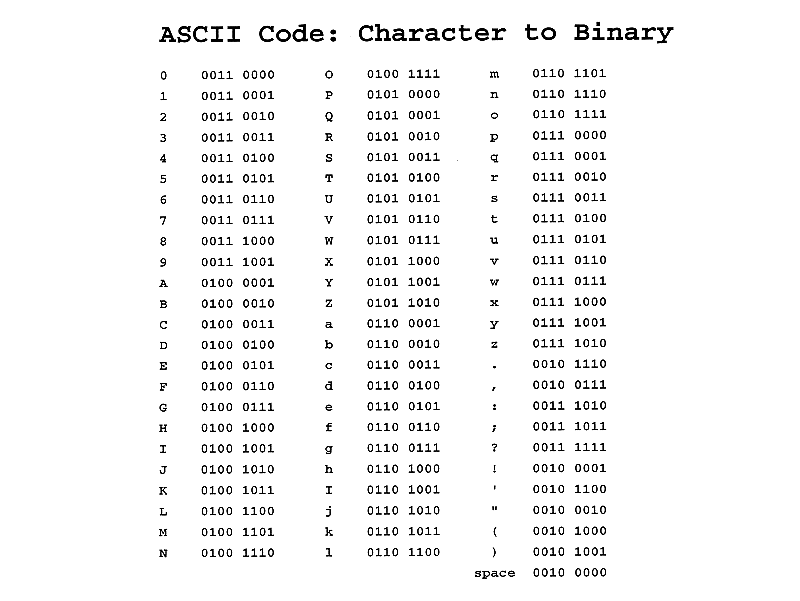
Ćirilica zauzima ni više ni manje po osam bita za svaki karakter.
Sramota, ali namerno neću da editujem, neka ostane. D se vidi kako "majstor plus_minus" lupi i ostade živ.
Ono što jeste tačno:
- Svaki ASCII karakter jeste `težak` jedan bajt ili 8 bit-a. A bit je kec ili nula. (slika u prilogu pojašnjava dodatno, šta je ASCII, ima tona materijala na netu o tome).
- Za ćirilicu mora više od `samo osam bita` po karakteru, jer je UNICODE *(utf-8 web standard) da tako kažemo - fleksibilan, pa će u nekim jezicima ići i po 2 ili 3 BAJTA za svaki karakter (i o tome ima tona materijala na izvol' te ...).
Evo dva primera.
Prvi, gde je reč `Latinica` napisana latinično (prvi primer) i drugi gde je reč `Latinica` ispisana ćirilicom.
Izraženo u binarnom, `sirovom` CPU formatu (ASCII/Unicode enkodiranje).
01001100 01100001 01110100 01101001 01101110 01101001 01100011 01100001
11010000 10011011 11010000 10110000 11010001 10000010 11010000 10111000 11010000 10111101 11010000 10111000 11010001 10000110 11010000 10110000
Zaključak je dakle da za ćirilicu treba po 2 bajta za svako slovo.
Zaključak je dakle da bi kompletna baza bila minimum - DUPLO veća.
Pa neka je sada, ovakva kakva je, mlatim -- nekih 2 terabajta .. a gabaritna *sql baza podataka ume da košta i to fino. (ovde već ne mlatim).
Uopšte - samo jedna dodatna *sql tabela - negde kod nekih hosting/sql provajdera košta i do 100 evra preko.
Pa neka ima i 3 recorda .. I tako ..
Možda je to Gojkov glavni razlog za nepostojanje ćirilice, arapskog, kineskog, japanskog.. pisma, a ne zato što je šatro `srbomrzac/domobran` i slične 3.14čke materine.
about:networking

