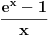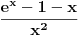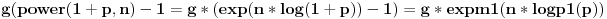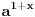Re: Programera k'o pleve, ali koliko upotrebljivih?
Re: Programera k'o pleve, ali koliko upotrebljivih?Citat:
Branko Santo: @ac1bd4
Ako ti nije problem da mi objasnis kakve veze asembler ima sa modernim programiranjem i zbog cega je bitan?
Da uzmes klinca iz gimnazije sa dobrim logickim razmisljanjem i 6 meseci ga obucavas + 6 meseci nekog segrtskog rada i eto ti programera. Vrlo je moguce da se i pre kraja tih 12 meseci biti spreman da radi kao junior programer.
Nije mi jasno uopste uzdizanje ovog fakulteta, onog fakulteta. Pa kao da za programera treba covek da bude doktor nauka. Uvek ce trebati siguran sam po neki programer koji je doktor matematike da pise kojekakve algoritme i izmislja svasta ali za stancanje klasa, funkcionalnosti i interfejsa definitivno nije potreban fakultet.
Ako ti nije problem da mi objasnis kakve veze asembler ima sa modernim programiranjem i zbog cega je bitan?
Da uzmes klinca iz gimnazije sa dobrim logickim razmisljanjem i 6 meseci ga obucavas + 6 meseci nekog segrtskog rada i eto ti programera. Vrlo je moguce da se i pre kraja tih 12 meseci biti spreman da radi kao junior programer.
Nije mi jasno uopste uzdizanje ovog fakulteta, onog fakulteta. Pa kao da za programera treba covek da bude doktor nauka. Uvek ce trebati siguran sam po neki programer koji je doktor matematike da pise kojekakve algoritme i izmislja svasta ali za stancanje klasa, funkcionalnosti i interfejsa definitivno nije potreban fakultet.
Delimicno se slazem sa tobom, assabler u danasnje vreme zaista malo kome treba, isto moze i da se kaze za C pa cak i za C++. Ali neka teorija algoritama je vise nego pozeljna, tek da ljudi znaju da postoji nekoliko razlicitih alhoritama za sortiranje. nekoliko razlicitih struktura podataka, da se recimo Mapa/Dictionary moze implementirati na nekoliko nacina. Zasto je neki od algoritama pogodniji je nesto sto bi programeri trebalo da znaju i da razumeju.