Učitaj "rečnik" u niz pre glavne petlje, koristi
in_array() za iterativnu pretragu u petlji.
Za dodatne performanse mada verujem da ti to neće biti potrebno možeš da okreneš niz rečnika tako da podaci budu ključevi preko
array_flip() čime dobijaš direktan pristup sa
isset() u glavnoj petlji što ti tu daje
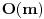
. Obrati pažnju da ako imaš različite linije sa istim sadržajem, nakon array_flip() samo jedna se čuva u nizu, ali po tvom kodu ovo ti neće ni na koji način smetati. Izmeri da li to radi brže.
Ako ti to ipak smeta ili ovo radi sporije (ako je array_flip spor), možeš da napišeš svoju funkciju za pakovanje koja dok redove iz rečnika smešta tokom učitavanja kao ključeve u asocijativan niz, a redove sa istim sadržajem u podniz. Ili ako ne želiš da koristiš asocijativan niz na ovaj način, možeš da izbegneš iterativnu pretragu u in_array tako što po učitavanju sortiraš niz sa redovima iz rečnika preko
sort() ili sortiraš datoteku unapred, i potom koristiš binarnu pretragu u glavnoj petlji što tu daje
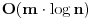
.
Ako ti prosto trebaju redovi koji su prisutni u obe datoteke, sortiraj obe i potom odradi upoređivanje premotavanjem. Dakle ako je trenutni red prve manji od druge, čitaš prvu, ako je veći čitaš iz druge, a ako je jednak imaš pogodak. Umesto
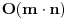
sada imaš samo
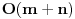
u glavnoj petlji. U memoriji se čuva samo po jedan red iz obe datoteke.
Moj komentar kao moderatora je da ako očekuješ korisne savete podeliš isečak iz pravog koda ili ako je ti to neki NDA dokument ne dozvoljava konstruišeš primer koji potpuno prati logiku koda koji sastavljaš. Ovako kada stalno ubacuješ nove elemente u zagonetku, niko ne može da ti stvarno pomogne i moraću da zaključam ovu temu. Na primer, siguran sam da si ovde imao u glavnoj petlji i neki fopen/fclose ili makar
rewind() za $h, ali u tvom primeru toga nema.
[Ovu poruku je menjao Goran Rakić dana 21.09.2010. u 03:55 GMT+1]
http://sr.libreoffice.org — slobodan kancelarijski paket, obrada teksta, tablice,
prezentacije, legalno bez troškova licenciranja

 Rad sa velikim tekstualnim dokumentima
Rad sa velikim tekstualnim dokumentima


 Re: Rad sa velikim tekstualnim dokumentima
Re: Rad sa velikim tekstualnim dokumentima
